Calcbench offers a huge amount of data to our subscribers, and sometimes that’s all a subscriber wants — reams and reams of historical data, that you can use to populate your own models and analytical tools.
Today we wanted to give curious readers a quick look at how that works. The place to start is our Standardized Metrics page.
This page lists all the specific pieces of financial data that Calcbench tracks: nearly 1,500 items, from universally known disclosures reported by everyone on the primary financial statements, to some truly obscure stuff disclosed by a relative few companies, only in the footnotes.
When you first arrive at the Standardized Metrics page, you’ll see something like Figure 1, below.
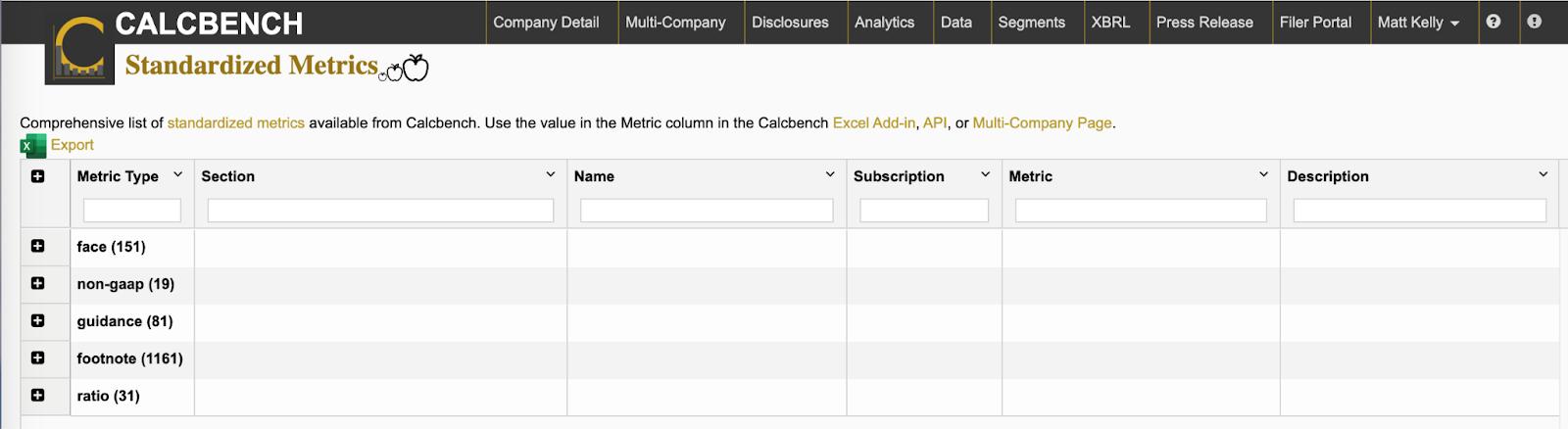
From there you can expand the menu for each of those five categories of data, to see a brief description of each data item we track. See Figure 2, which shows some of the non-GAAP disclosures we track.
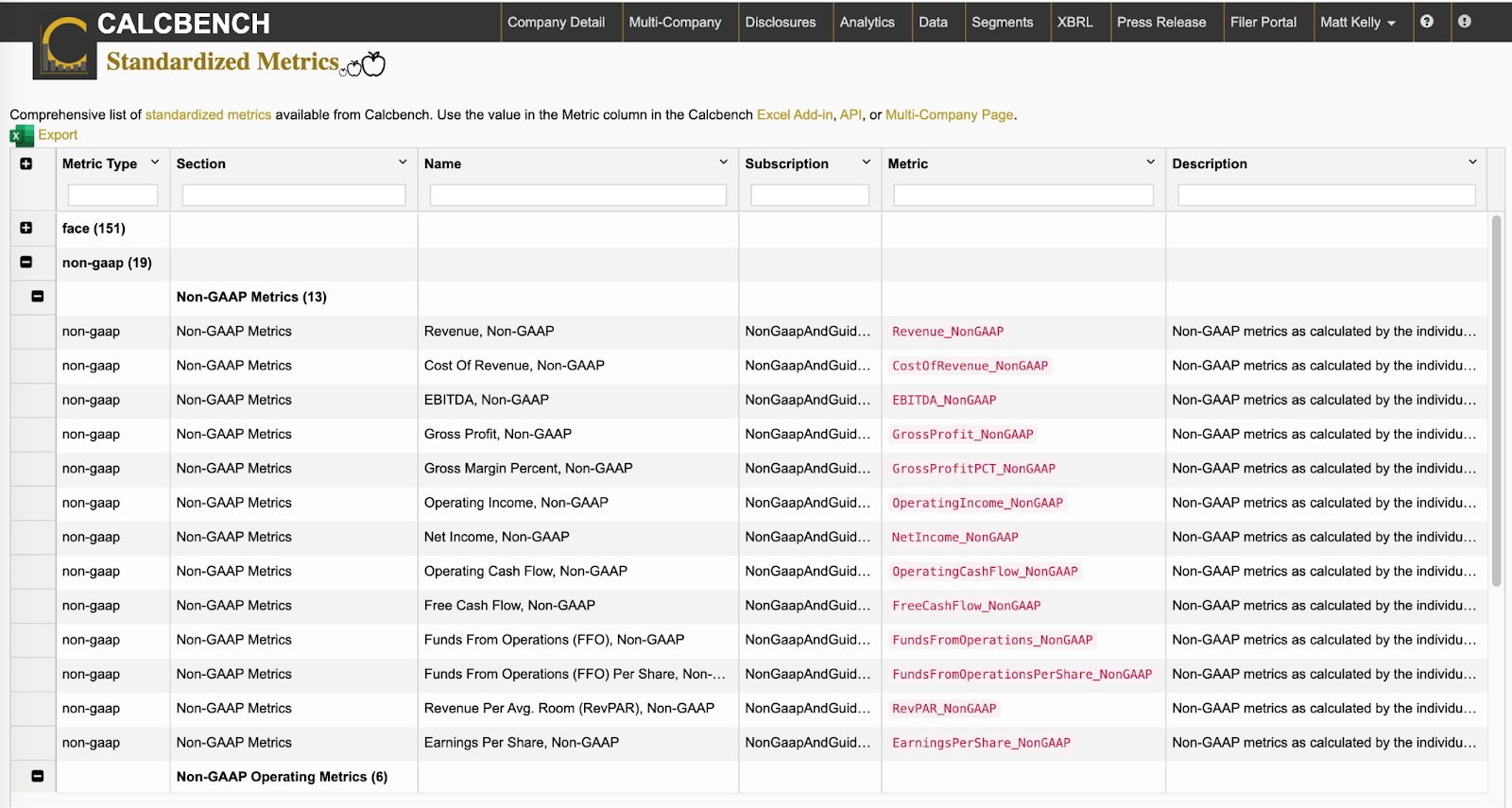
From there you can select or de-select the specific data items you want to include in your models.
An important point here is that when you identify certain data you want to collect, Calcbench provides all instances of that data for as far back as the company reported it. So for example, if you wanted to pull 120 points of data for a large accelerated filer, you’d receive every instance of all 120 individual data points — and for a large filer, that could go as far back as 2008, when companies first started publishing their financial disclosures in machine-readable format. You could easily have 10,000 pieces of information to populate your model.
How It Works
To be clear, this material is for Calcbench subscribers who subscribe to and use our API. With a bit of Python programming in a Jupyter notebook, you can build a routine that specifies exactly what data you want for some company you’re researching. Then execute that routine, and your model fills up with all the data Calcbench has.
For example, say you want to build a historical model of financial disclosures for Labcorp Holdings ($LH), an object would be returned that might look like Figure 3, below.
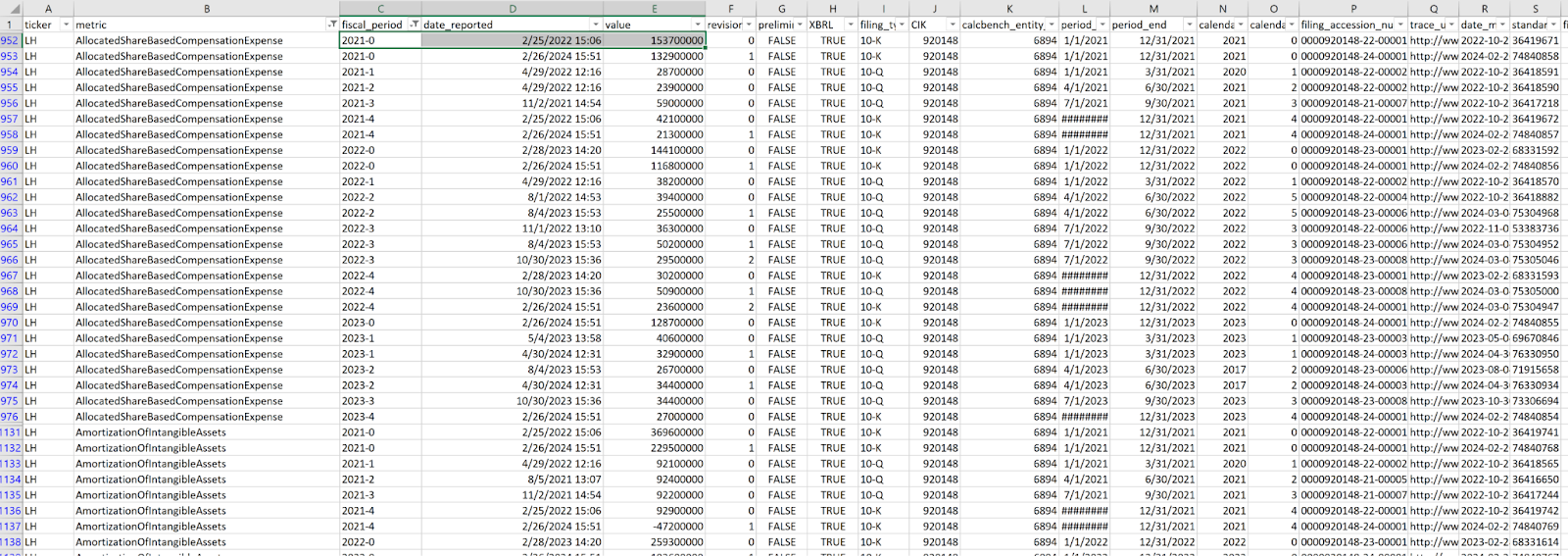
Zooming in on the very first items in the upper-left corner, you see:

We’re looking at what Labcorp disclosed for share-based expense (that is, equity compensation) for a few periods in 2021. But look closely: Labcorp made two separate disclosures for the period “2021-0,” which is the period of the whole year. First Labcorp reported an expense of $153.7 million on Feb. 25, 2022; and then it reported an expense of $132.9 million on Feb. 26, 2024.
What’s that about? Labcorp revised its share-based expense disclosure between 2022 and 2024. You can even see that the second, revised disclosure is flagged as such, under the column that says “revision.”
Why is that useful? Because if your firm wants to model Labcorp’s financial performance through a certain period of time — say, from 2017 to 2023 — you’d need that number originally reported in 2022; the updated 2024 number wouldn’t have existed in the timeframe for your model.
You could also look at all that data from other angles. Our first example only looked at one item, share-based compensation expense, across multiple periods. Figure 4, below, shows multiple disclosure items for only one period.
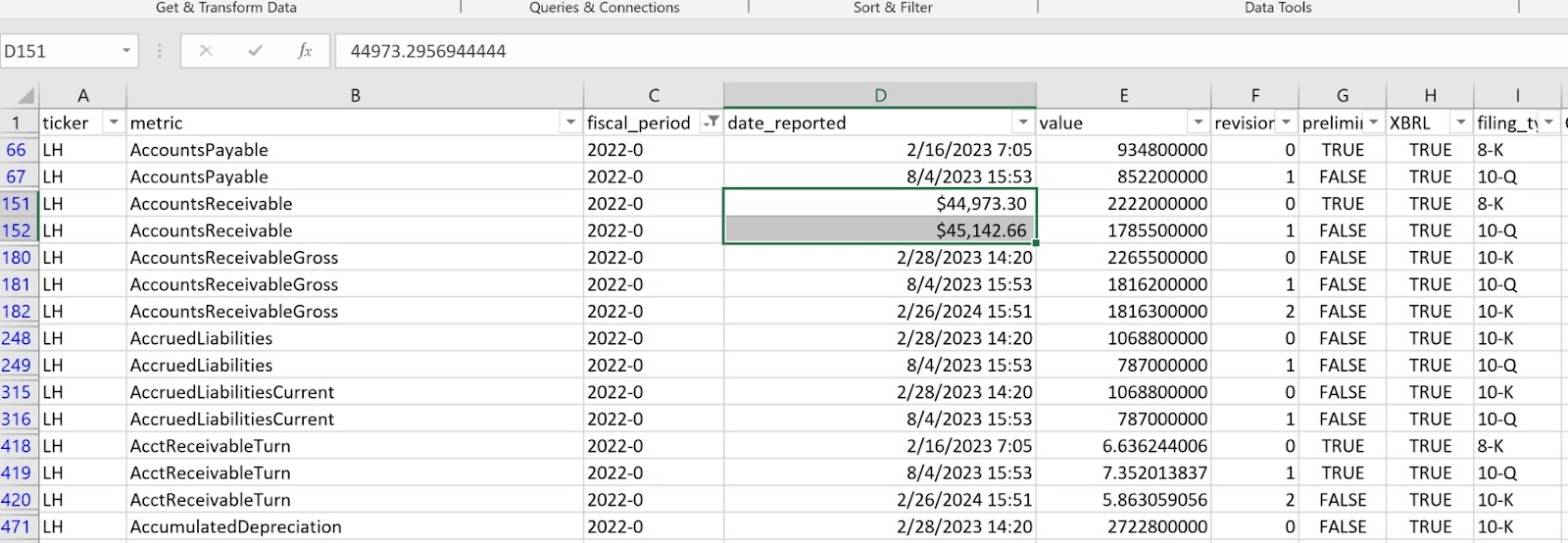
Again, notice that you can track the data as originally filed and as subsequently revised, if that’s information you need to know.
That’s just one example of how Calcbench can help you build point-in-time models, with exquisite amounts of precision in the data you want to include. Look for more examples sometime in the future— and for anyone who wants to get started with API-level analysis but has questions, always feel free to contact us at us@calcbench.com.